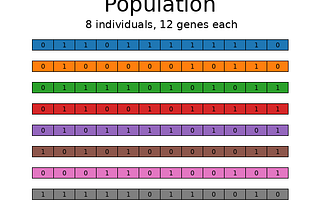
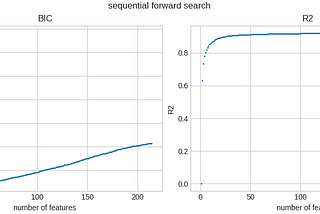
Florin AndreiinTowards Data ScienceEfficient feature selection via genetic algorithmsUsing evolutionary algorithms for fast feature selection with large datasetsJan 124Jan 124
Florin AndreiinTowards Data ScienceEfficient feature selection via CMA-ES (Covariance Matrix Adaptation Evolution Strategy)Using evolutionary algorithms for fast feature selection with large datasetsJan 121Jan 121
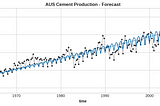
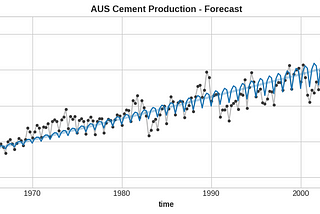
Florin AndreiinTowards Data ScienceModeling variable seasonal features with the Fourier transformImprove time series forecast performance with a technique from signal processingOct 12, 20231Oct 12, 20231
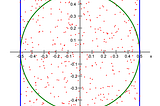
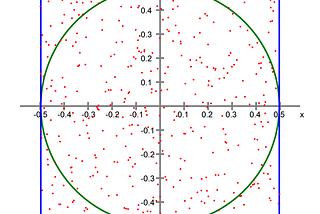
Florin AndreiinTowards Data ScienceVisualizing the full extent of the curse of dimensionalityUsing the Monte Carlo method to visualize the behavior of observations with very large numbers of featuresJun 29, 20232Jun 29, 20232
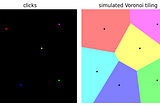
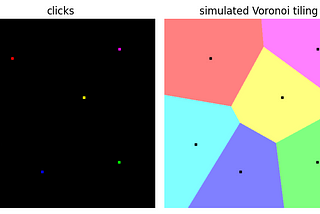
Florin AndreiinTowards Data ScienceTrain Image Segmentation Models to Accept User Feedback via Voronoi Tiling, Part 2How to train an off-the-shelf image segmentation model to respond to user feedback.May 5, 2023May 5, 2023
Florin AndreiinTowards Data ScienceTrain Image Segmentation Models to Accept User Feedback via Voronoi Tiling, Part 1How to train an off-the-shelf image segmentation model to respond to user feedback.May 5, 2023May 5, 2023
Florin AndreiinTowards Data ScienceUsing quantum annealing for feature selection in scikit-learnFeature selection for scikit-learn models, for datasets with many features, using quantum processingApr 10, 2023Apr 10, 2023
Florin AndreiinTowards Data ScienceQuantum Computing for Optimization Problems — Solving the Knapsack ProblemHow to solve an optimization problem using quantum computing, compared to a traditional solution.Jan 16, 20231Jan 16, 20231
Florin AndreiinTowards Data ScienceUse simulations to optimize customer wait time, systems load, and costExperiments are too expensive? Use simulations instead.Feb 26, 20222Feb 26, 20222
Florin AndreiinTowards Data ScienceData has many periodic components you need to visualize? Treat it like audio!Visualize periodic components using the Fourier transform.Aug 29, 2021Aug 29, 2021